Fine Tuning
Based on the capabilities of DevPod, we provide images that are specifically dedicated to model fine-tuning, making it convenient for users to fine-tune their own models.
The process of creating a fine-tuning job is basically the same as that of DevPod. You can refer to the creation process of DevPod. Here are several differences:
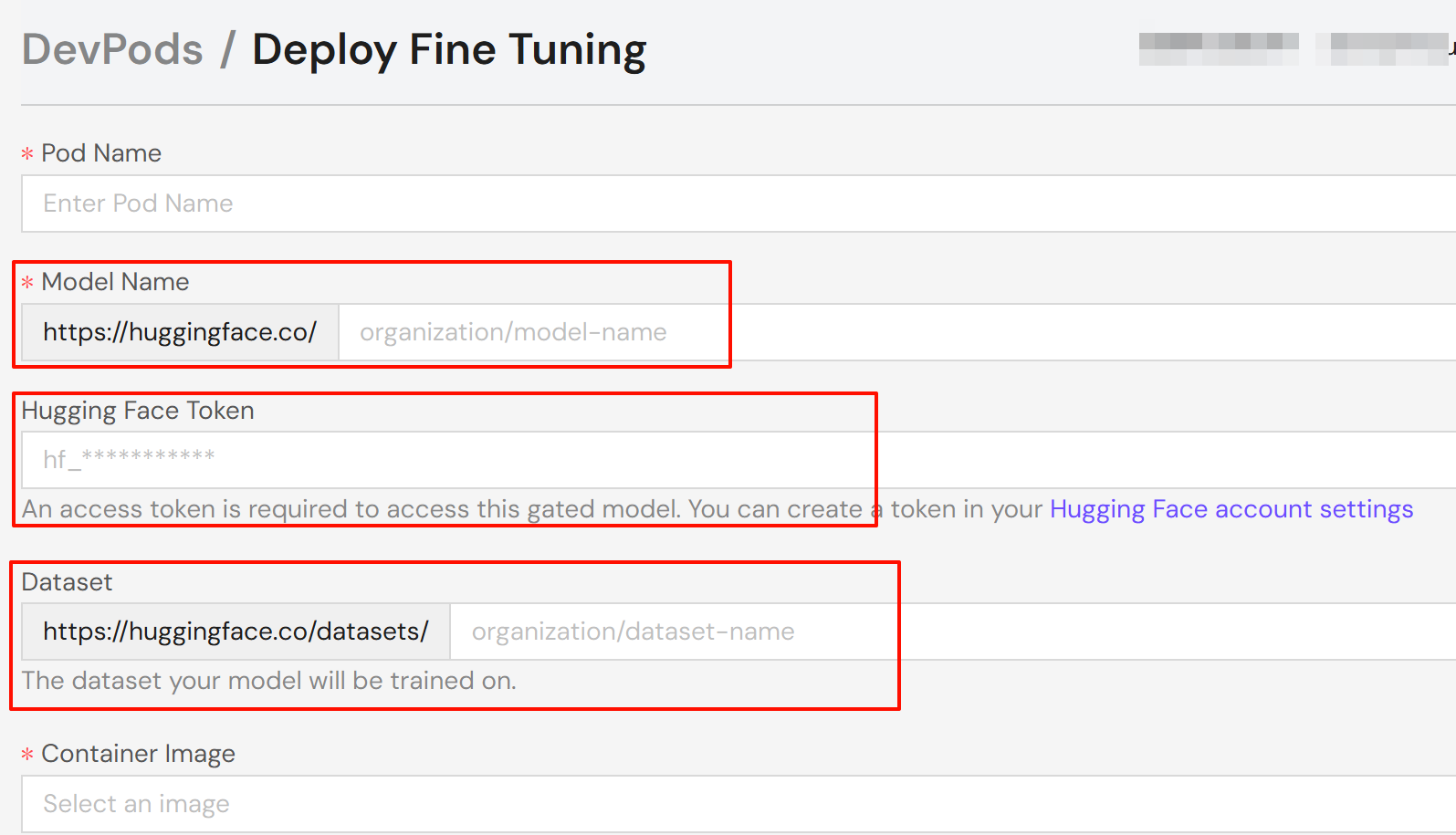
- You need to enter the base model for fine-tuning on the creation page, for example: Qwen/Qwen3-8B.
- If the model requires a access token, you also need to fill in the Hugging Face token (optional).
- Enter your chosen dataset identifier in the Dataset field, for example: tatsu-lab/alpaca.
After selecting the configuration of the task resources, deploy the pod and wait until the task status changes to "running". Click Connect and choose your preferred connection method:
- Jupyter Notebook: Browser-based notebook interface (recommended).
- Web Terminal: Browser-based terminal.
- SSH: Local machine terminal connection.
Note:
To use SSH, add your public SSH key in your account settings. The system automatically adds your key to the pod's authorized_keys file.
At present, we have carefully prepared two tool images, which are developed based on Axolotl and Torchtune respectively, aiming to provide convenience for users to fine-tune models. Next, we will introduce in detail the usage processes of these two images respectively.
Based on Axolotl
Configure your environment
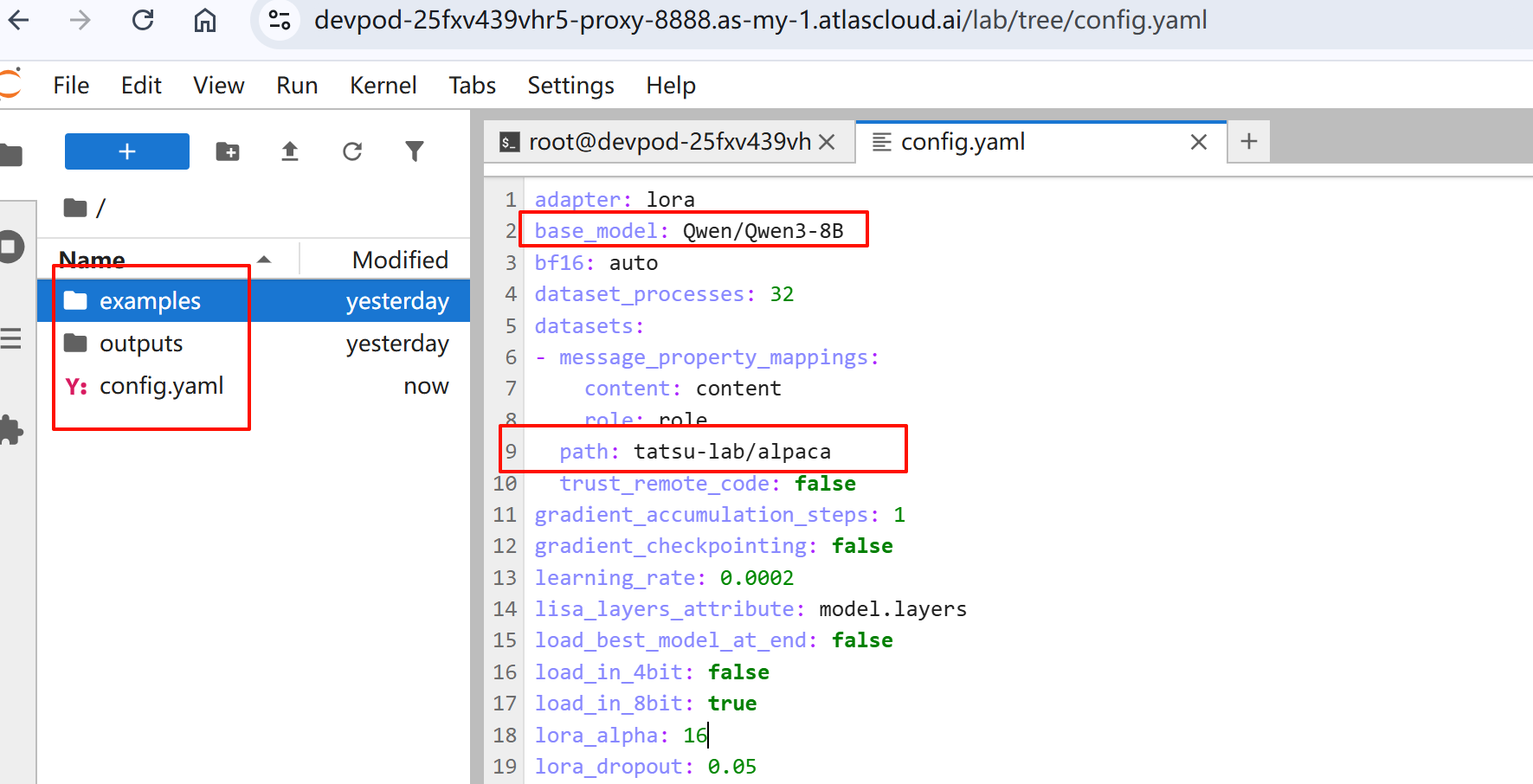
Open the Jupyter Notebook in the browser. You can see that there are three files in the working directory:
- examples/: Sample configurations and scripts
- outputs/: Training results and model outputs
- config.yaml: Training parameters for your model The system generates an initial config.yaml based on your selected base model and dataset.
Review and modify the configuration
Review and adjust the parameters based on your specific use case. Here's an example configuration with common parameters:
base_model: Qwen/Qwen3-32B
# Automatically upload checkpoint and final model to HF
# hub_model_id: username/custom_model_name
plugins:
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
strict: false
chat_template: qwen3
datasets:
- path: mlabonne/FineTome-100k
type: chat_template
split: train[:20%]
field_messages: conversations
message_property_mappings:
role: from
content: value
val_set_size: 0.0
output_dir: ./outputs/out
dataset_prepared_path: last_run_prepared
sequence_len: 2048
sample_packing: true
eval_sample_packing: true
pad_to_sequence_len: true
load_in_4bit: true
adapter: qlora
lora_r: 16
lora_alpha: 32
lora_target_modules:
- q_proj
- k_proj
- v_proj
- o_proj
- down_proj
- up_proj
lora_mlp_kernel: true
lora_qkv_kernel: true
lora_o_kernel: true
wandb_project:
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 2
micro_batch_size: 1
num_epochs: 1
optimizer: adamw_torch_4bit
lr_scheduler: cosine
learning_rate: 0.0002
bf16: auto
tf32: true
gradient_checkpointing: offload
gradient_checkpointing_kwargs:
use_reentrant: false
resume_from_checkpoint:
logging_steps: 1
flash_attention: true
warmup_steps: 10
evals_per_epoch: 4
saves_per_epoch: 1
weight_decay: 0.0
special_tokens:
For more configuration examples, visit the Axolotl examples repository.
Start the fine-tuning process
Once your configuration is ready, follow these steps:
- Start the training process:
axolotl train config.yaml
- Monitor the training progress in your terminal.
Based on Torchtune
Configure your environment
Open the Jupyter Notebook in the browser. You can use tune ls to list the complete set of fine-tuning recipes supported by torchtune.
RECIPE CONFIG
full_finetune_single_device llama2/7B_full_low_memory
code_llama2/7B_full_low_memory
llama3/8B_full_single_device
llama3_1/8B_full_single_device
llama3_2/1B_full_single_device
llama3_2/3B_full_single_device
mistral/7B_full_low_memory
phi3/mini_full_low_memory
phi4/14B_full_low_memory
qwen2/7B_full_single_device
qwen2/0.5B_full_single_device
qwen2/1.5B_full_single_device
qwen2_5/0.5B_full_single_device
qwen2_5/1.5B_full_single_device
qwen2_5/3B_full_single_device
qwen2_5/7B_full_single_device
llama3_2_vision/11B_full_single_device
full_finetune_distributed llama2/7B_full
llama2/13B_full
llama3/8B_full
llama3_1/8B_full
llama3_2/1B_full
llama3_2/3B_full
llama3/70B_full
llama3_1/70B_full
llama3_3/70B_full
llama3_3/70B_full_multinode
mistral/7B_full
gemma/2B_full
gemma/7B_full
gemma2/2B_full
gemma2/9B_full
gemma2/27B_full
phi3/mini_full
phi4/14B_full
qwen2/7B_full
qwen2/0.5B_full
qwen2/1.5B_full
qwen2_5/0.5B_full
qwen2_5/1.5B_full
qwen2_5/3B_full
qwen2_5/7B_full
llama3_2_vision/11B_full
llama3_2_vision/90B_full
lora_finetune_single_device llama2/7B_lora_single_device
llama2/7B_qlora_single_device
code_llama2/7B_lora_single_device
code_llama2/7B_qlora_single_device
llama3/8B_lora_single_device
llama3_1/8B_lora_single_device
llama3/8B_qlora_single_device
llama3_2/1B_lora_single_device
llama3_2/3B_lora_single_device
llama3/8B_dora_single_device
llama3/8B_qdora_single_device
llama3_1/8B_qlora_single_device
llama3_2/1B_qlora_single_device
llama3_2/3B_qlora_single_device
llama2/13B_qlora_single_device
mistral/7B_lora_single_device
mistral/7B_qlora_single_device
gemma/2B_lora_single_device
gemma/2B_qlora_single_device
gemma/7B_lora_single_device
gemma/7B_qlora_single_device
gemma2/2B_lora_single_device
gemma2/2B_qlora_single_device
gemma2/9B_lora_single_device
gemma2/9B_qlora_single_device
gemma2/27B_lora_single_device
gemma2/27B_qlora_single_device
phi3/mini_lora_single_device
phi3/mini_qlora_single_device
phi4/14B_lora_single_device
phi4/14B_qlora_single_device
qwen2/7B_lora_single_device
qwen2/0.5B_lora_single_device
qwen2/1.5B_lora_single_device
qwen2_5/0.5B_lora_single_device
qwen2_5/1.5B_lora_single_device
qwen2_5/3B_lora_single_device
qwen2_5/7B_lora_single_device
qwen2_5/14B_lora_single_device
llama3_2_vision/11B_lora_single_device
llama3_2_vision/11B_qlora_single_device
lora_dpo_single_device llama2/7B_lora_dpo_single_device
llama3_1/8B_lora_dpo_single_device
lora_dpo_distributed llama2/7B_lora_dpo
llama3_1/8B_lora_dpo
full_dpo_distributed llama3_1/8B_full_dpo
ppo_full_finetune_single_device mistral/7B_full_ppo_low_memory
lora_finetune_distributed llama2/7B_lora
llama2/13B_lora
llama2/70B_lora
llama2/7B_qlora
llama2/70B_qlora
llama3/8B_dora
llama3/70B_lora
llama3_1/70B_lora
llama3_3/70B_lora
llama3_3/70B_qlora
llama3/8B_lora
llama3_1/8B_lora
llama3_2/1B_lora
llama3_2/3B_lora
llama3_1/405B_qlora
mistral/7B_lora
gemma/2B_lora
gemma/7B_lora
gemma2/2B_lora
gemma2/9B_lora
gemma2/27B_lora
phi3/mini_lora
phi4/14B_lora
qwen2/7B_lora
qwen2/0.5B_lora
qwen2/1.5B_lora
qwen2_5/0.5B_lora
qwen2_5/1.5B_lora
qwen2_5/3B_lora
qwen2_5/7B_lora
qwen2_5/32B_lora
qwen2_5/72B_lora
llama3_2_vision/11B_lora
llama3_2_vision/11B_qlora
llama3_2_vision/90B_lora
llama3_2_vision/90B_qlora
dev/lora_finetune_distributed_multi_dataset dev/11B_lora_multi_dataset
generate generation
dev/generate_v2 llama2/generation_v2
llama3_2_vision/11B_generation_v2
dev/generate_v2_distributed llama3/70B_generation_distributed
llama3_1/70B_generation_distributed
llama3_3/70B_generation_distributed
dev/early_exit_finetune_distributed llama2/7B_full_early_exit
eleuther_eval eleuther_evaluation
llama3_2_vision/11B_evaluation
qwen2/evaluation
qwen2_5/evaluation
gemma/evaluation
phi4/evaluation
phi3/evaluation
mistral/evaluation
llama3_2/evaluation
code_llama2/evaluation
quantize quantization
qat_distributed llama2/7B_qat_full
llama3/8B_qat_full
qat_lora_finetune_distributed llama3/8B_qat_lora
llama3_1/8B_qat_lora
llama3_2/1B_qat_lora
llama3_2/3B_qat_lora
knowledge_distillation_single_device qwen2/1.5_to_0.5B_KD_lora_single_device
llama3_2/8B_to_1B_KD_lora_single_device
knowledge_distillation_distributed qwen2/1.5_to_0.5B_KD_lora_distributed
llama3_2/8B_to_1B_KD_lora_distributed
Review and modify the configuration
- Copy the configuration file to the local device. for example:
tune cp qwen2_5/3B_lora_single_device config.yaml
- Modify, Review and adjust the parameters based on your specific use case.
Start the fine-tuning process
Once your configuration is ready, follow these steps:
- Start the training process:
tune run lora_finetune_single_device --config config.yaml
- Monitor the training progress in your terminal.
Related documents
For more information about fine-tuning with Axolotl, see:
For more information about fine-tuning with Torchtune, see:
For more information about freer and more flexible fine-tuning courses, see: