vLLM
Create Storage
First, create a persistent storage volume to store model files:
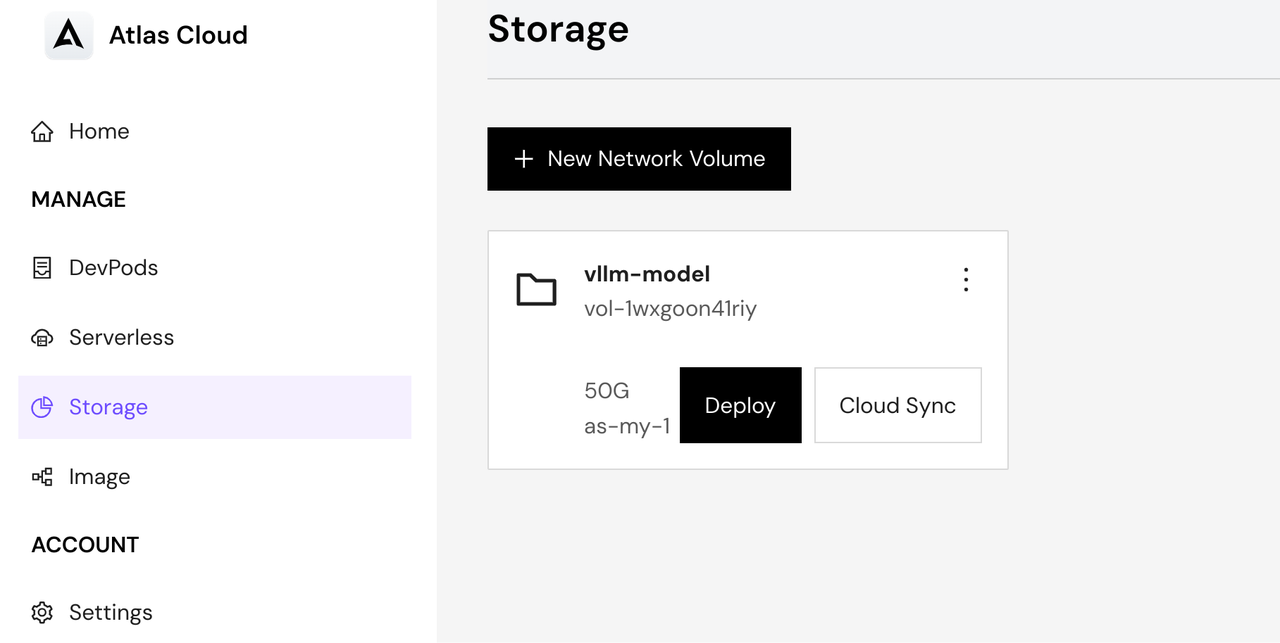
- Navigate to the Storage page
- Click "New Network Volume" button
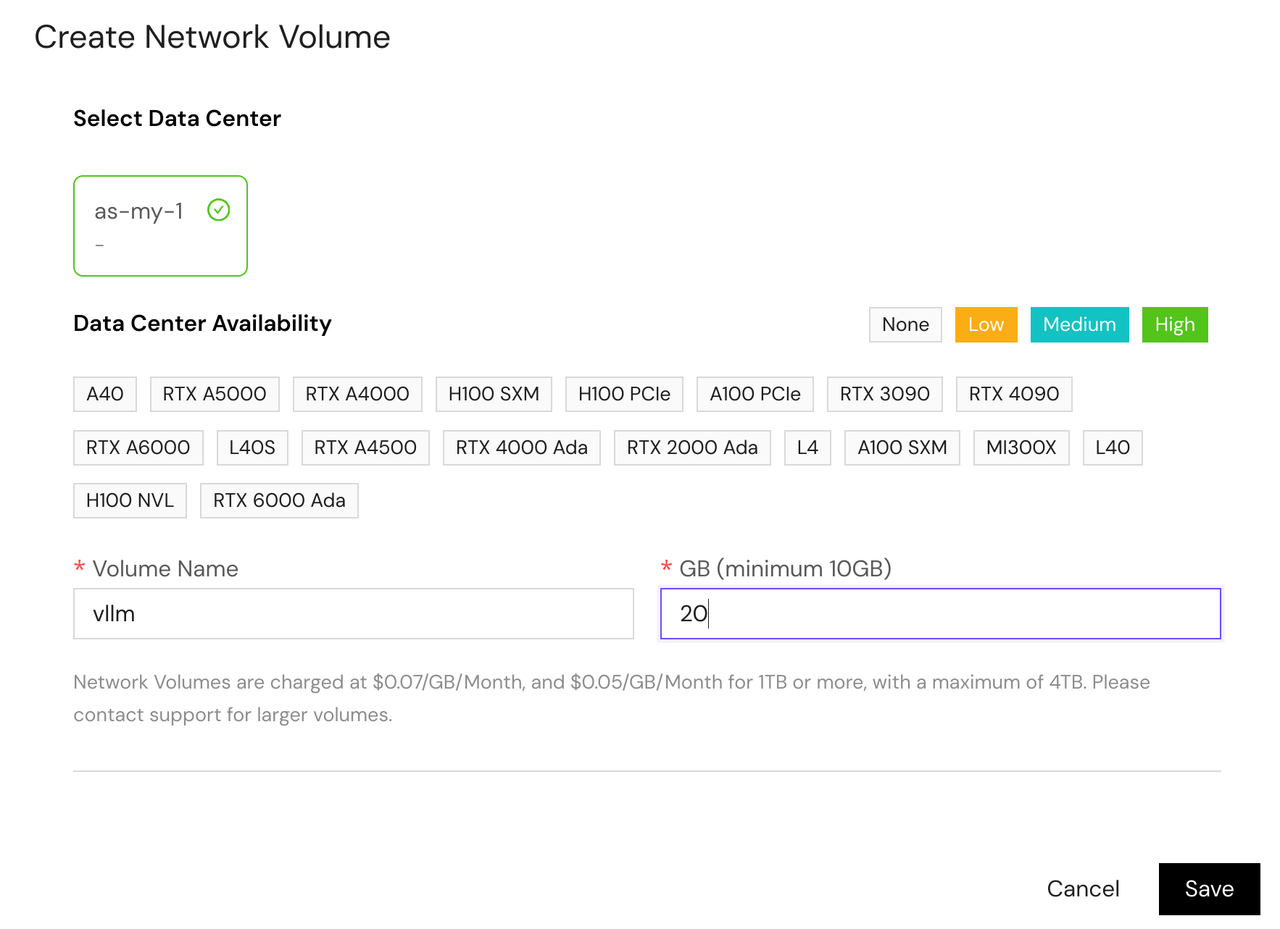
- Fill in the storage details:
- Volume Name: Give your storage a descriptive name
- GB: Choose appropriate size based on your model requirements
- Data Center: Choose the same region where you'll deploy your serverless
Get HuggingFace Token
To download models from HuggingFace, you'll need an access token:
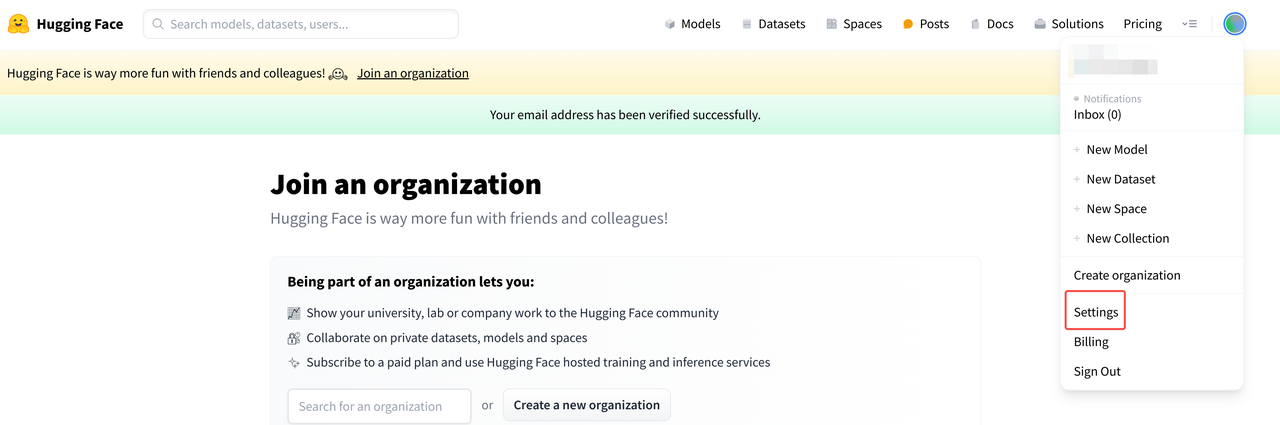
- Visit HuggingFace website and sign in to your account
- Go to your profile settings
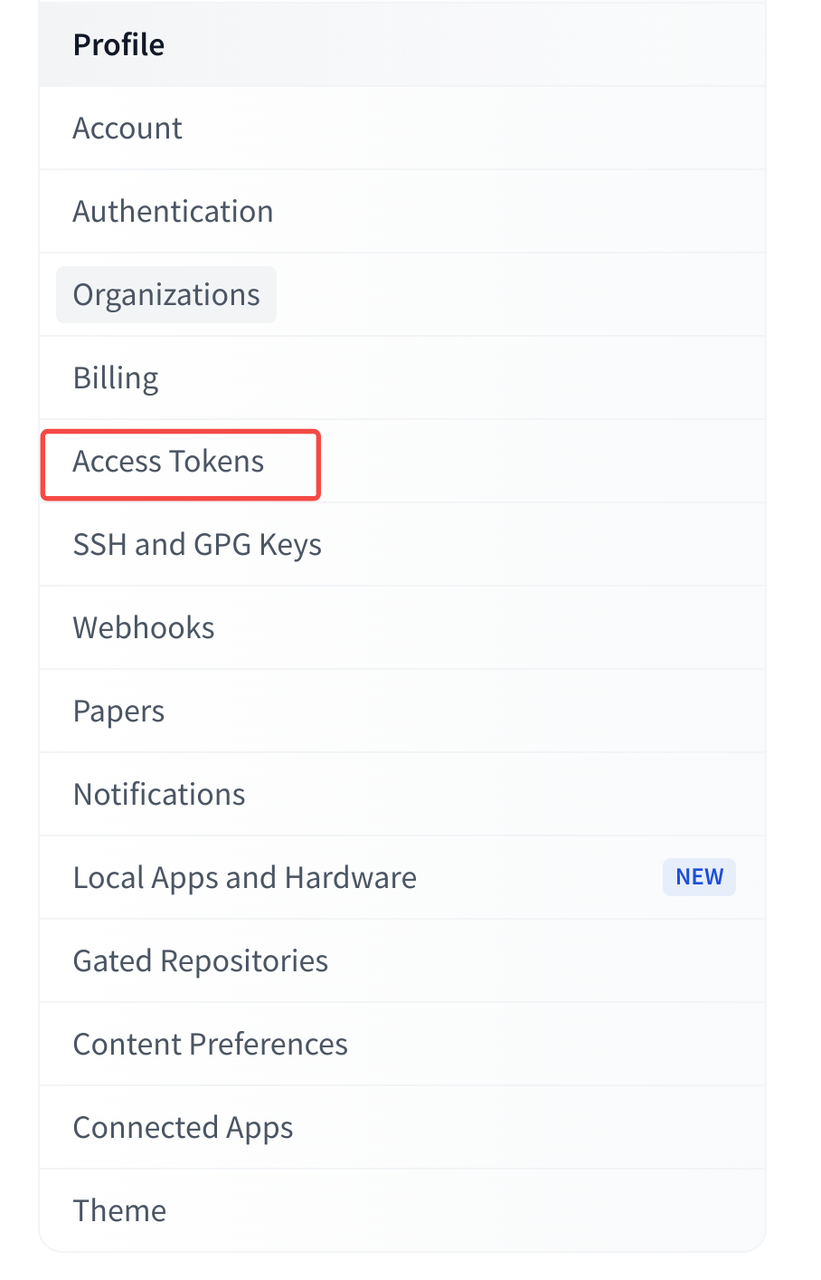
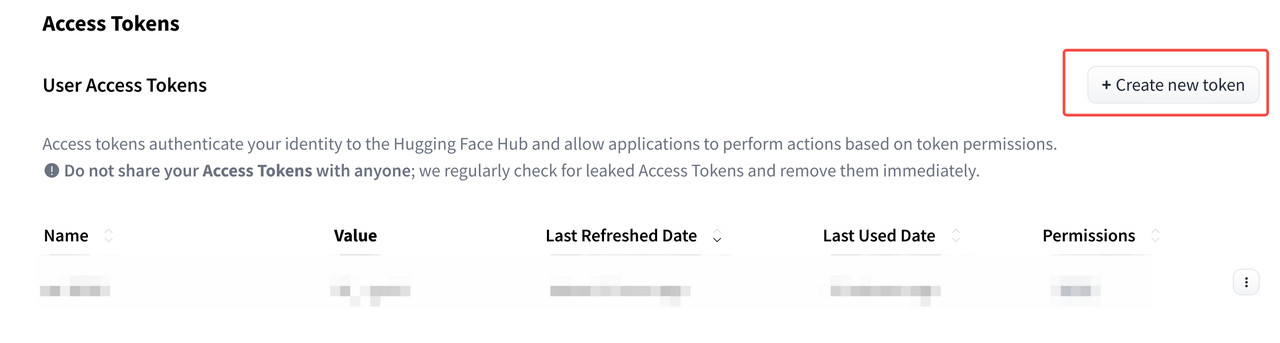
- Navigate to "Access Tokens" section
- Click "Create new token" button
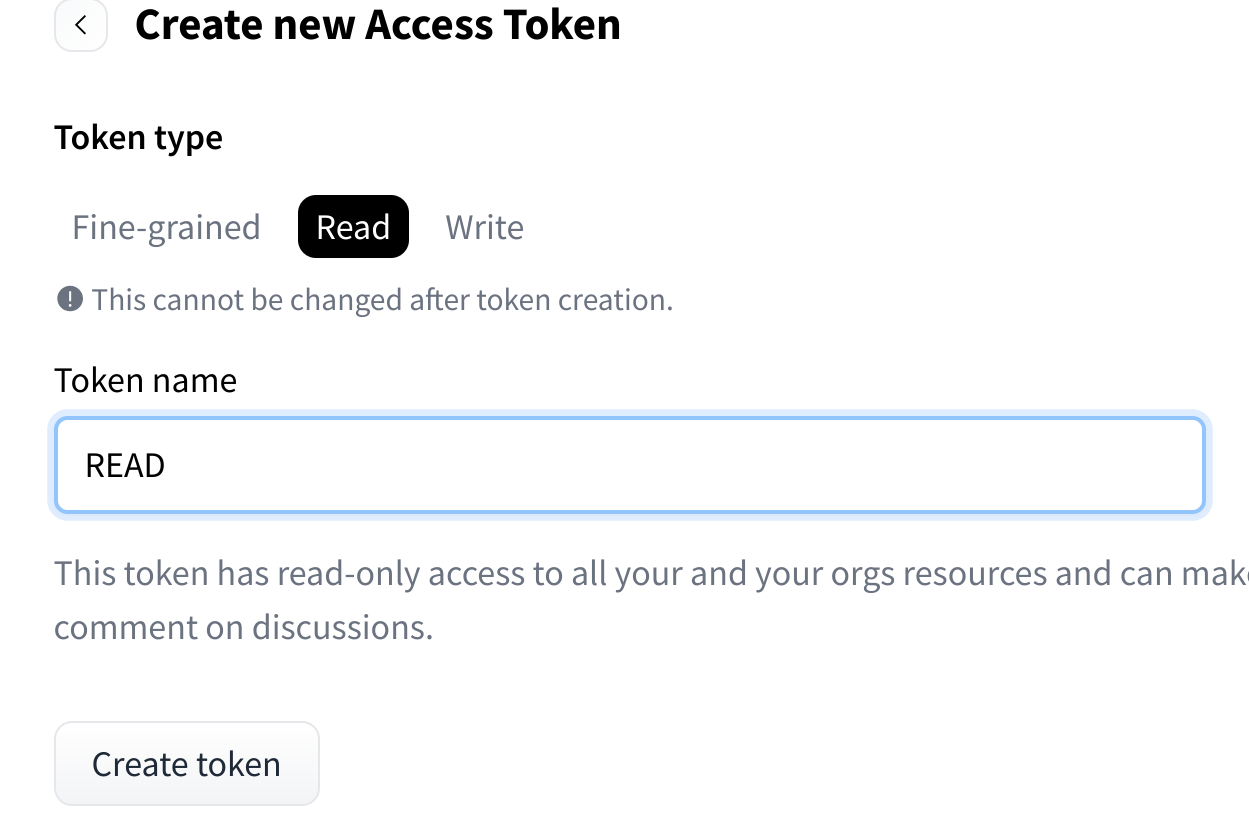
- Configure your token:
- Name: Give your token a descriptive name
- Role: Select "read" for model downloading
- Click "Create token" button
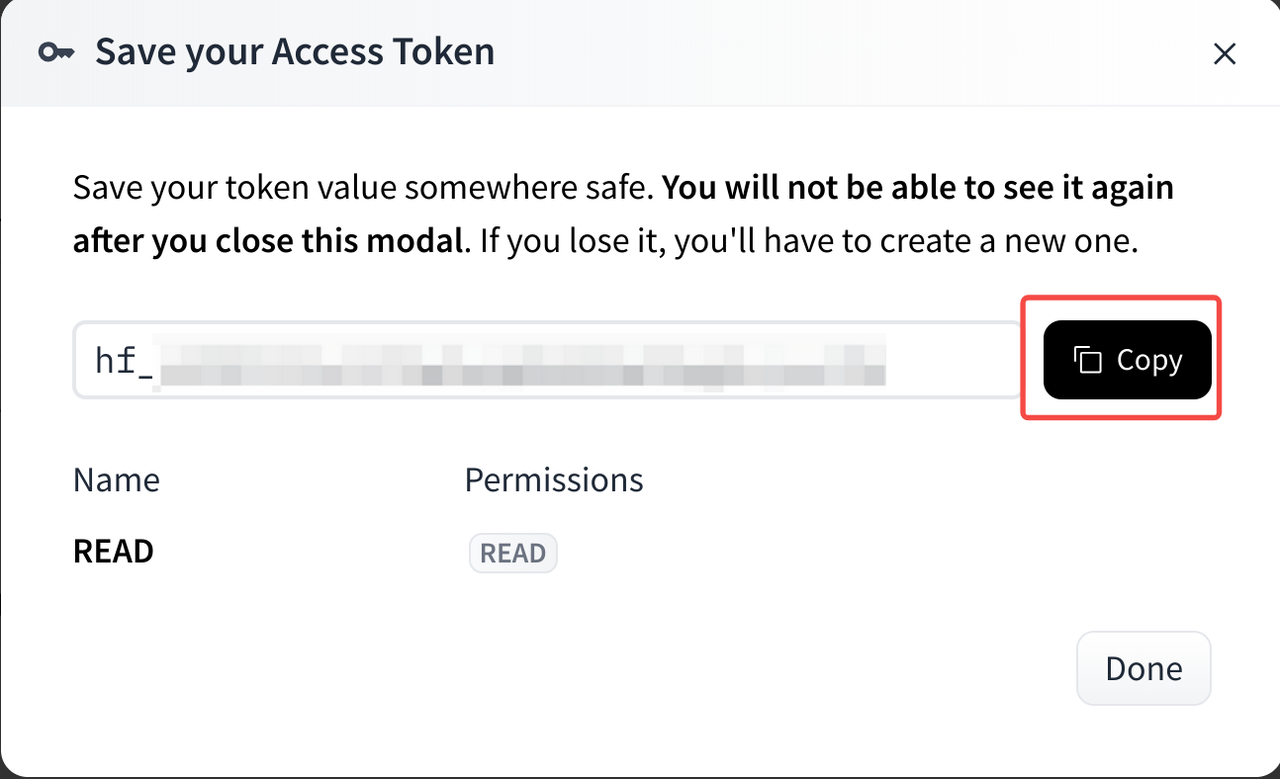
- Copy and save the generated token securely - you'll need it later
Configuration Guide
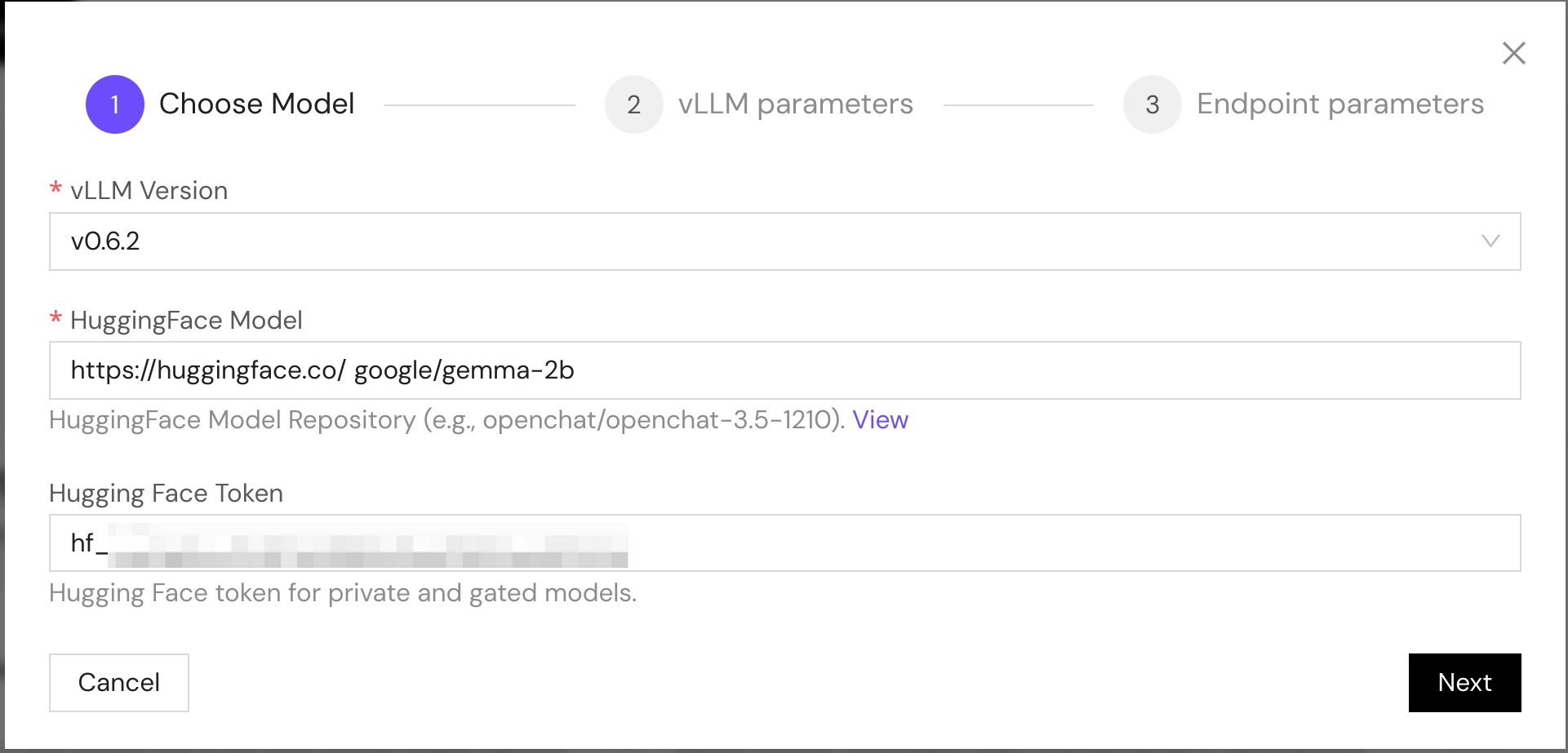
Choose Model
The platform provides a built-in vLLM framework version 0.6.2 environment. Here's what you need to configure:
- HuggingFace Model: Enter the target model name (e.g., meta-llama/Llama-2-7b-chat-hf)
- HuggingFace Token: Optional authentication token
- Required for certain models and datasets
- Automatically set as
HUGGING_FACE_HUB_TOKENenvironment variable in the container - Paste the token you generated earlier
vLLM Parameters
These are optional advanced settings for the vLLM framework. Modify with caution:
- Tensor Parallel Degree: For multi-GPU inference
- Max Total Tokens: Limit the total response length
- Quantization: Model compression options
- Trust Remote Code: Enable for models requiring custom code
Note: Please ensure you understand these parameters before modifying them from their default values.
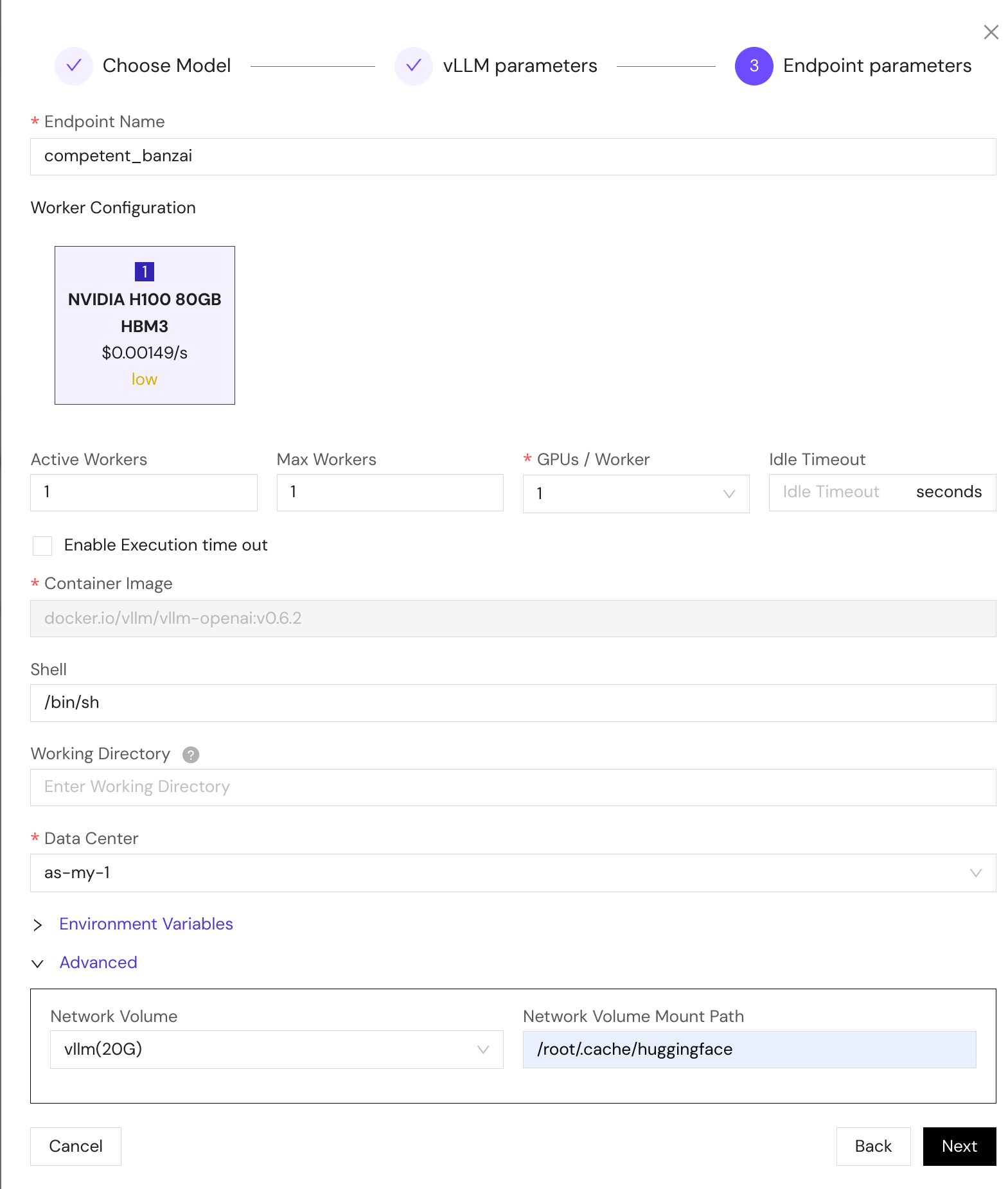
Endpoint Parameters
Configure your deployment environment:
- Endpoint Name: Auto-generated but customizable
- GPU Configuration:
- Select GPU type (A100, H100, L4, etc.)
- Specify number of GPUs per worker
- Data Center: Choose deployment region
- Storage:
- Strongly recommended: Mount Network Volume to
/root/.cache/huggingface - This enables model persistence across restarts
- Speeds up subsequent deployments by caching model files
- Strongly recommended: Mount Network Volume to
Tip: Persistent storage significantly improves startup time for subsequent deployments by avoiding repeated model downloads.
After deployment, your vLLM endpoint will be ready to serve inference requests. The system will automatically handle model downloading and initialization.